
SDXL プロンプトガイド:制御のための技術マニュアル
Stable Diffusion XL (SDXL) はおもちゃではありません。スタジオです。ユーザーが何を望んでいるかを推測する他のモデルとは異なり、SDXL は正確なエンジニアリングを必要とします。デュアルテキストエンコーダーの制御方法、特定の解像度「バケット」の構文を習得し、プロンプトの重み付けを使用して AI に重要事項を集中させる方法を学びます。
画像をアップロード → SDXL プロンプトを取得内部構造:CLIP G+L アーキテクチャ
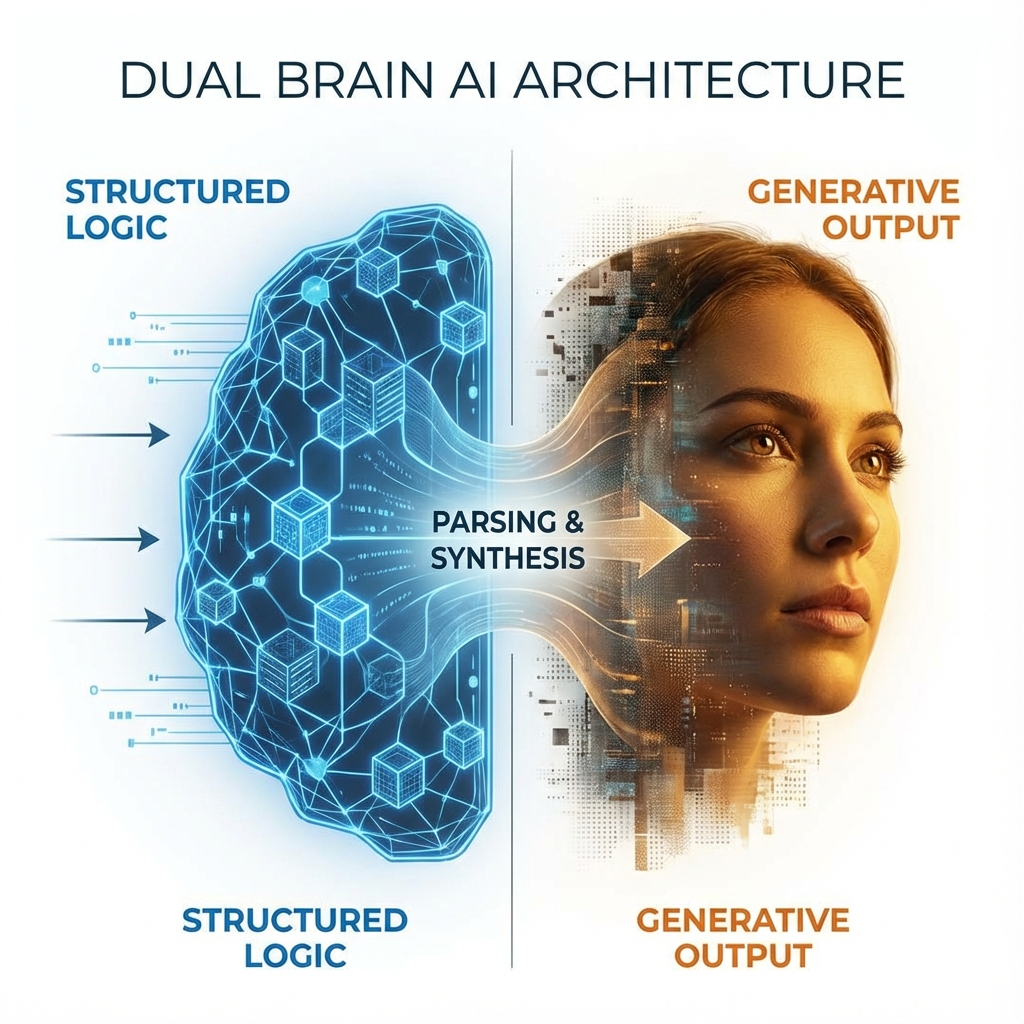
SDXL は、2つのテキストエンコーダー(CLIP ViT-L と OpenCLIP ViT-bigG)を同時に使用するという点でユニークです。2つの脳が並行して働いていると考えてください。1つは主題の単純で自然な言語記述に焦点を当て、もう1つは抽象的な概念、キーワード、芸術的なスタイルに焦点を当てています。
つまり、プロンプトは両方を満たす必要があります。短くパンチの効いた文が「G」エンコーダーを落ち着かせ、特定のタグのリストが「L」エンコーダーを落ち着かせます。物語を求める Flux とは異なり、SDXL は構造化された仕様を求めています。また、構文を厳密に尊重します。(parentheses:1.2) を使用して注目度を高めることは提案ではなく、モデルへの数学的命令です。
コントロールボード設定
| 設定 | 推奨値 | 重要性 |
|---|---|---|
| 解像度 (Buckets) | 1024x1024, 1152x896, 896x1152 | SDXL は特定の「バケット」でトレーニングされました。これらから逸脱すると、画像が焼き付いたりトリミングされたりします。標準比率を守ってください。 |
| ステップ数 (Steps) | 30-50 | 例:速度重視なら 30、最大詳細なら 50。50を超えても価値はほとんど増えず、時間がかかるだけです。 |
| CFG スケール (CFG Scale) | 7.0 - 8.0 | どれだけ真剣に聞くか。高すぎる (>9) と画像が焼き付きます。低すぎる (<5) とプロンプトを無視します。 |
| サンプラー (Sampler) | DPM++ 2M Karras | SDXL のゴールドスタンダード。高速で詳細。Euler a はよりソフト/高速ですが、詳細は少なくなります。 |
ワークフロー:エンジニアのパイプライン
- ベースプロンプト(主題):自然言語で核心となる主題を明確に定義します。例:'A robot barista pouring coffee'。
- 修飾スタック(スタイル):2番目のエンコーダー用にカンマ区切りのタグを追加します。例:'cyberpunk, neon lights, 8k, octane render'。
- 重み付け制御:最も重要な要素を特定し、それを強化します。コーヒーが欠けている場合は、'(pouring coffee:1.3)' に変更します。
- ネガティブプロンプトシールド:SDXL には何をしてはいけないかを伝える必要があります。標準のネガティブエンベディングまたはリストを追加します:'text, watermark, blurry, deformed hands'。
設計されたプロンプトテンプレート
重み付けハック(フォーカスブースター)
Positive
Formula: (Main Subject:1.2), [Action], [Context], [Style Tags] なぜ機能するのか:時々、SDXL はプロンプトの一部を無視します。それを (parentheses) に入れると、注目スコアが 1.1 倍になります。数字 :1.2 や :1.5 を追加すると、モデルはそのトークンを他のすべてのトークンよりも優先するよう強制されます。 Example: '(Red sports car:1.3) drifting on a racetrack, smoke, motion blur, 8k uhd, dslr'
Negative
blue car, slow, parked, cartoon
「ブレイク」テクニック(概念混合)
Positive
Formula: [Concept A] BREAK [Concept B] なぜ機能するのか:互いに滲むことなく、2つの異なる色や概念を混ぜたい場合(青いシャツと赤いパンツなど)、キーワード BREAK を使用します。これによりコンテキストウィンドウがリセットされ、モデルは次のチャンクを独立して処理してからマージするよう強制されます。 Example: 'A woman with blue hair BREAK wearing a red dress'
Negative
purple dress, green hair
「ネガティブシールド」(品質ブースター)
Positive
Formula: [Prompt] ... Negative: text, watermark, bad anatomy, blurry, low quality, cropped なぜ機能するのか:SDXL には DALL-E 3 のような組み込みの「品質フィルター」がありません。膨大なトレーニングセットに含まれる「ゴミ」データ(透かし、ぼやけた写真)を除外するには、ネガティブプロンプトを提供する必要があります。 Example: 'An astronaut on mars. Negative: helmet reflection, text, nasa logo, malformed limbs'
Negative
text, watermark, bad anatomy, blurry, low quality, cropped
ケーススタディ:SDXL の精度
ケーススタディ 1:シュルレアリスム構図
SDXL は抽象的な概念を美しく扱います。「スチームパンクの街」と「クジラ」が、古いモデルによくあるアーティファクトなしに自然に融合していることに注目してください。

a giant whale floating in the sky above a steampunk city, golden clouds, dreamlike atmosphere, surrealism, intricate details, oil painting style --w 1024 --h 1024
ケーススタディ 2:構図制御(「ブレイク」テクニック)
BREAK キーワードを使用することで、主題の説明とスタイル/ムード設定を分離し、芸術的なスタイルが主題の詳細を妨げないようにすることができます(例:メガネと帽子が明確に保たれる)。

a white fluffy dog wearing round glasses and a blue cap BREAK artistic painting style, warm color palette, simple background, soft lighting, shallow depth of field
SDXL トラブルシューティング
画像がトリミングされたり重複したりするのはなぜですか?
間違った解像度を使用している可能性があります。SDXL はランダムなサイズ(512x512など)を嫌います。常に「バケット」を使用してください:1024x1024、1152x896、1216x832、1344x768、1536x640。一貫した画像を得るには、これらの比率を守ってください。
「リファイナー (Refiner)」とは何ですか?
リファイナーは、ベースモデルの後に実行してノイズを除去するように設計された2番目のモデルです。しかし、多くの最新ワークフロー(および ImgtoPrompt)はベースモデルのプロンプトを非常に適切に最適化するため、リファイナーは不要な場合が多いです。私たちは、ベースプロンプトを正しくすることに焦点を当てています。
「Danbooru」タグは使えますか?
はい!Midjourney とは異なり、SDXL は人気のあるイメージボードタグ(1girl、upper_body、looking_at_viewer など)を認識します。これらを自然言語と混ぜるのが、多くの場合最も強力なプロンプトの出し方です。
Continue Exploring
SDXL プロンプトをエンジニアリングする
重みや構文を推測してクレジットを無駄にしないでください。リファレンス画像をアップロードすれば、私たちが完璧で重みバランスの取れた SDXL プロンプトを構築します。
SDXL プロンプトを自動生成